Sequential 모델은 계층을 선형으로 쌓은 것입니다.
다음과 같이 계층 인스턴스 리스트를 생성자에 전달하여 Sequential 모델을 만들 수 있습니다:
Notice
<aside> 💡 CodeOnWeb에서는 따로 파이썬을 설치하지 않더라도 코드박스 아래의 실행 버튼을 클릭하여 바로 파이썬 코드를 실행해볼 수 있습니다. TensorFlow, Theano와 같은 백엔드 코드도 마찬가지로 설치 없이 실행 버튼만 눌러 실행할 수 있습니다. 'Keras 연습하기' 과정에서는 실행 결과까지 출력하는 예제 코드에 대해서만 실행하여 결과를 확인할 수 있도록 하였습니다.
</aside>
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential([
Dense(32, input_shape=(784,)),
Activation('relu'),
Dense(10),
Activation('softmax'),
])
.add() 메소드를 이용해 계층을 쉽게 추가할 수도 있습니다:
model = Sequential()
model.add(Dense(32, input_dim=784))
model.add(Activation('relu'))
모델은 어떤 형태의 입력이 들어올지 알아야 합니다. 이러한 이유로 Sequential 모델의 첫 번째 계층(이후 계층은 자동으로 모양을 추론할 수 있으므로 첫 번째 계층만 해당)에 입력 형태에 대한 정보를 제공해야 합니다. 이를 수행할 수 있는 몇 가지 방법이 있습니다:
input_shape 인수를 전달합니다. 이것은 형태 정보를 담은 튜플입니다(정수 또는 None을 항목으로 가지는 튜플인데, None은 임의의 양의 정수를 나타냅니다). input_shape에 batch 차원은 포함되지 않습니다.Dense와 같은 일부 2차원 계층은 input_dim 인수를 통해 입력 형태를 지정할 수 있으며, 일부 3차원 시간 계층(temporal layers)는 input_dim과 input_length 인수를 지원합니다.batch_size 인수를 전달할 수 있습니다. batch_size = 32와 input_shape = (6, 8)을 한 계층에 같이 전달하면 모든 입력 batch가 (32, 6, 8)의 형태를 가질 것으로 기대합니다.따라서 다음 두 코드는 완전히 같습니다:
model = Sequential()
model.add(Dense(32, input_shape=(784,)))
model = Sequential()
model.add(Dense(32, input_dim=784))
모델을 학습하기 전에 compile 메소드를 통해 학습 과정을 구성해야 합니다. 이 메소드는 세 가지 인수를 받아들입니다.
rmsprop 또는 adagrad 등)를 나타내는 문자열 식별자, 또는 Optimizer 클래스의 인스턴스가 될 수 있습니다. 최적화기를 참조하십시오.categorical_crossentropy 또는 mse 등)일 수도 있고 목표 함수 자체일 수도 있습니다. 손실을 참조하십시오.metrics = ['accuracy']로 설정하는 것이 좋습니다. 메트릭은 기본 제공되는 메트릭 또는 사용자 정의 메트릭 함수의 문자열 식별자가 될 수 있습니다.# For a multi-class classification problem
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# For a binary classification problem
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
# For a mean squared error regression problem
model.compile(optimizer='rmsprop',
loss='mse')
# For custom metrics
import keras.backend as K
def mean_pred(y_true, y_pred):
return K.mean(y_pred)
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy', mean_pred])
Keras 모델은 Numpy 배열로 이루어진 입력 데이터 및 레이블을 기반으로 훈련합니다. 모델을 훈련할 때는 일반적으로 fit 함수를 사용합니다. 자세한 것은 [모델] Sequential를 참조하십시오.
# For a single-input model with 2 classes (binary classification):
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
# Generate dummy data
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(2, size=(1000, 1))
# Train the model, iterating on the data in batches of 32 samples
model.fit(data, labels, epochs=10, batch_size=32)
# For a single-input model with 10 classes (categorical classification):
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# Generate dummy data
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(10, size=(1000, 1))
# Convert labels to categorical one-hot encoding
one_hot_labels = keras.utils.to_categorical(labels, num_classes=10)
# Train the model, iterating on the data in batches of 32 samples
model.fit(data, one_hot_labels, epochs=10, batch_size=32)
다차원(multi-class) softmax 분류를 위한 Multilayer Perceptron (MLP):
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.optimizers import SGD
import keras.utils
# Generate dummy data
import numpy as np
x_train = np.random.random((1000, 20))
y_train = keras.utils.to_categorical(np.random.randint(10, size=(1000, 1)), num_classes=10)
x_test = np.random.random((100, 20))
y_test = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
model = Sequential()
# Dense(64) is a fully-connected layer with 64 hidden units.
# in the first layer, you must specify the expected input data shape:
# here, 20-dimensional vectors.
model.add(Dense(64, activation='relu', input_dim=20))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy',
optimizer=sgd,
metrics=['accuracy'])
model.fit(x_train, y_train,
epochs=20,
batch_size=128)
score = model.evaluate(x_test, y_test, batch_size=128)
이진(binary) 분류를 위한 MLP:
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout
# Generate dummy data
x_train = np.random.random((1000, 20))
y_train = np.random.randint(2, size=(1000, 1))
x_test = np.random.random((100, 20))
y_test = np.random.randint(2, size=(100, 1))
model = Sequential()
model.add(Dense(64, input_dim=20, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_train, y_train,
epochs=20,
batch_size=128)
score = model.evaluate(x_test, y_test, batch_size=128)
VGG-like 합성곱신경망:
import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.optimizers import SGD
# Generate dummy data
x_train = np.random.random((100, 100, 100, 3))
y_train = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
x_test = np.random.random((20, 100, 100, 3))
y_test = keras.utils.to_categorical(np.random.randint(10, size=(20, 1)), num_classes=10)
model = Sequential()
# input: 100x100 images with 3 channels -> (100, 100, 3) tensors.
# this applies 32 convolution filters of size 3x3 each.
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(100, 100, 3)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd)
model.fit(x_train, y_train, batch_size=32, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=32)
LSTM을 이용한 시퀀스 분류:
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.layers import Embedding
from keras.layers import LSTM
model = Sequential()
model.add(Embedding(max_features, output_dim=256))
model.add(LSTM(128))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=16, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=16)
1차원 합성곱을 이용한 시퀀스 분류:
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.layers import Embedding
from keras.layers import Conv1D, GlobalAveragePooling1D, MaxPooling1D
model = Sequential()
model.add(Conv1D(64, 3, activation='relu', input_shape=(seq_length, 100)))
model.add(Conv1D(64, 3, activation='relu'))
model.add(MaxPooling1D(3))
model.add(Conv1D(128, 3, activation='relu'))
model.add(Conv1D(128, 3, activation='relu'))
model.add(GlobalAveragePooling1D())
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=16, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=16)
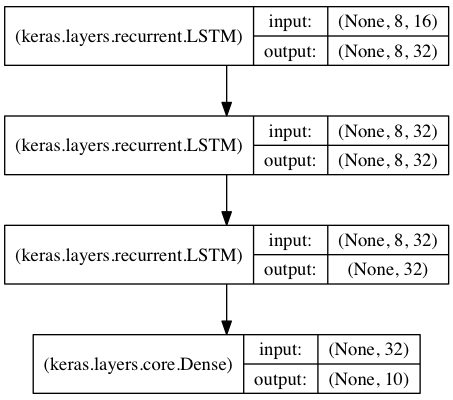
Stacked LSTM을 이용한 서열 분류
이 모델에서는 3개의 LSTM 계층을 쌓아 올려, 모델이 좀 더 고수준의 시간 정보를 학습하게 합니다.
첫 두 LSTM은 전체 출력 시퀀스를 반환하는 반면 마지막 LSTM은 출력 시퀀스의 마지막 단계만 반환해서 시간 차원을 삭제합니다(즉 입력 시퀀스를 하나의 벡터로 변환).
from keras.models import Sequential
from keras.layers import LSTM, Dense
import numpy as np
data_dim = 16
timesteps = 8
num_classes = 10
# expected input data shape: (batch_size, timesteps, data_dim)
model = Sequential()
model.add(LSTM(32, return_sequences=True,
input_shape=(timesteps, data_dim))) # returns a sequence of vectors of dimension 32
model.add(LSTM(32, return_sequences=True)) # returns a sequence of vectors of dimension 32
model.add(LSTM(32)) # return a single vector of dimension 32
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
# Generate dummy training data
x_train = np.random.random((1000, timesteps, data_dim))
y_train = np.random.random((1000, num_classes))
# Generate dummy validation data
x_val = np.random.random((100, timesteps, data_dim))
y_val = np.random.random((100, num_classes))
model.fit(x_train, y_train,
batch_size=64, epochs=5,
validation_data=(x_val, y_val))
"상태"를 재사용하는 stacked LSTM 모델